Veeam がいよいよ、2 つの仮想化プラットフォームに的を絞り始めたので、自分のラボ環境に Microsoft Hyper-V を導入する方法を考えなければならない時期がやってきたと思い、VMware 仮想マシンで Hyper-V を実行できるかどうか知りたいと思いました。Veeam は、例えば、VMware Workstation にネストされたラップトップで稼働するポータブル ラボを使用することにより、ソリューションの提供に大きな成功を収めています。多くの場合、単一のラップトップで、ネストされた ESX サーバー、vCenter、DC、および Veeam アプリケーションを稼働させているので、Hyper-V もその中に含めることができるかどうか知りたいと思いました。
「この記事は、ハウツー ガイドとして、VMware Workstation 8 または ESXi 5 のいずれかで Hyper-V 仮想マシンを実行するためのプロセスをステップ順に説明しています。」
私は長い間、そんなことは不可能だと聞かされていましたが、数か月前、ESXi 5 が発表されれば可能になるという噂を小耳にはさみました。また、Intel Nehalem または Intel Core i7 で稼働する ESXi 5 では、ネストされたハイパーバイザーにさらに 64 ビットの仮想マシンをネストできるということも聞きました。このため、まず、新しいラップトップにしたら、この Intel アーキテクチャ、または同等の AMD をシステムに導入して、それを確認してみることにしました。イベントで使用する予定のアーキテクチャと同じアーキテクチャを持つラボ環境も何とか構築できました。
http://www.vcritical.com/2011/07/vmware-vsphere-can-virtualize-itself/#comment-12442
http://www.virtuallyghetto.com/2011/07/how-to-enable-support-for-nested-64bit.html
やっと試すチャンスがやってきたときには、ESXi は GAステータスに達していました。上記のブログを読んでわかったことは、すばらしい助言はあるが、その指示に従うと、数人が報告しているように、画面はただ真っ黒なままでした。追加の情報を提供したにもかかわらず、何の回答もありません。そこで、別の方法を試してみることにしました。ESXi 5 の代わりに VMware Workstation 8 をインストールすることにしたのです。ネストされた Hyper-V 仮想マシンはやっと稼働するようになりました。このときわかったことは、私が使用しているハードウェアは、ネストする Hyper-V と互換性があるということです。上記のブログ記事では、Hyper-V を稼働させる鍵となるのは、Intel EPT と呼ばれる CPU/BIOS 内の機能であると書かれていました。また、Nehalem/Core i7 があれば、Intel EPT を使用できると書かれていました。ただし、このブログ記事には、BIOS を通じて Intel EPT を有効にする必要があると書かれていました。しかし、私のいずれのシステム BIOS にも、このオプションがありません。
そこで、私は、どうすればうまくいくかをテストしている最中に、スタンドアロンの Hyper-V 製品をインストールする代わりに、Windows 2008 R2 Standard を使用して、Hyper-V をロールとして有効にすることにしました。ただ楽をするためにやったことでしたが、スタンドアロンの Hyper-V 製品もオプションとして問題なく使用できます。
VMware Workstation 8 での Hyper-V 仮想マシンのネスティング
ここで、VMware Workstation 8 で稼働するMicrosoft Hyper-V 仮想マシン(VM)を作成するための手順を以下に示しますが、その後で、VM をESXi 5 で作成する場合の手順も示します。
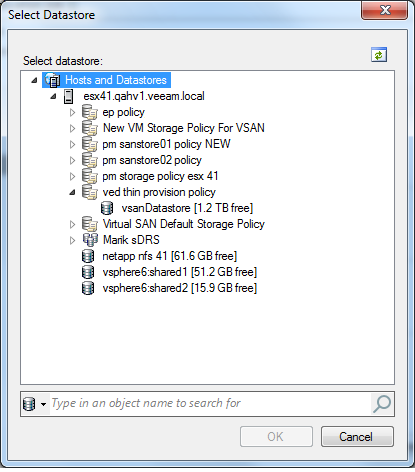
- バージョン8 のハードウェアで新しい VM を作成します。

- 4 GB の RAM および2 x vCPU と、Hyper-V の下にネストしたい VM の数に応じて約 80~100 GB のディスク領域を確保します。
- 多くのインストール ガイドでは、ゲスト OS として VMware ESX オプションを選択するように指示されていますが、それはやめてください。代わりに、Windows 2008 R2 x64 を選択します。

- 完了したら、Hyper-V 仮想ネットワークとして使用される別の NIC を VM に追加します。
- [仮想マシン] > [設定]> [プロセッサ] をクリックして、Intel VT-x/EPT 機能を通過するためのオプションをチェックします。

- VM が Windows 2008 R2 x64 のメディア ISO から起動するように設定します。
- VM を起動する前に、config ファイル .vmx を編集し、次のパラメーターを追加する必要があります。 hypervisor.cpuid.v0 = “FALSE”

- 起動し、Windows 2008 R2 x64 をインストールします。
- インストールが完了したら、サーバー マネージャを開いて、[ロールの追加] をクリックします。

- [Hyper-V] オプションを選択して、インストールします。この時点で、システムが正常に機能しているかどうか、Intel EPT 機能を通過するかを確認します。そうでなければ、先に進むことはできません。

- 仮想ネットワークに使用するネットワーク アダプターも選択する必要があります。

- ここで、Hyper-V をインストールします。再起動が必要です。
- インストールが完了したら、 サーバー マネージャを開き、Hyper-V までドリルダウンして、ローカル サーバーに接続します。

- 最後に、VM を作成し、インストールします。完了したら、VM を通常どおり使用できるようになります。ただし、速度は遅くなります。










ESXi 5 での Hyper-V仮想マシンのネスティング
ESXi 5 の場合、一部の手順は VMware の場合と同じですが、同じ作業でも多少面倒になります。
- まず、ESXi 5 のテック サポート モードにある /etc/vmware/config ファイルに入力する必要があります。私は、vSphere Client のセキュリティ プロファイルを使用して SSH を有効にした後、PuTTY SSHを使用して ESXi システムに入りました。
- そこから、ネストされたハイパーバイザーを許可するために必要な次のコマンドを実行しました。
# echo 'vhv.allow = "TRUE" ' >> /etc/vmware/config
コマンドラインでの一重引用符および二重引用符の使用に注意してください。
- 次に、バージョン 8 のハードウェア、4 GB(または使用可能な空き領域)、2 x vCPU、2 以上のvNIC、および 100 GB の仮想ディスクを使用して仮想マシン(VM)を作成します。
- 仮想マシンの設定に戻り、[オプション] > [CPU/MMU 仮想化] をクリックして、Intel VT-x/EPT 機能を通過するためのオプションをチェックします。


コマンドラインを使用してこの 2 行を追加するには、SSH に戻り、Hyper-V の VM をインストールするディレクトリに変更します。
# echo 'vhv.allow = "TRUE" ' >> /etc/vmware/config
この例では、config ファイルの名前を Hyper-V.vmx にしました。次のコマンドを入力します。
# echo 'monitor.virtual_exec = "hardware" ' >> Hyper-V.vmx
# echo 'hypervisor.cpuid.v0 = "FALSE" ' >> Hyper-V.vmx - 仮想マシンの設定に戻り、[オプション] > [CPU/MMU 仮想化] をクリックして、Intel VT-x/EPT 機能を通過するためのオプションをチェックします。

- 次に [オプション] 領域の [CPUID マスク]で、[詳細] をクリックします。

- 次の CPU マスク レベル ECXを追加します。---- ---- ---- ---- ---- ---- --H- ----

- Hyper-V または Windows 2008 R2 をインストールし、Hyper-V のロールを有効にします。
- 以上で、準備が完了しました。





ヒント
最後に、途中で失敗しないために、Ricky からのヒントをいくつか紹介します。
- システムに OS として Microsoft Hyper-V をインストールした後、再起動が必要です。Hyper-V をインストールした後に再起動すると、ブルー画面になりますが、慌てることはありません。Hyper-V を実際に使用する際にはブルー画面になりません。
- サーバーとラップトップの両方で、システムが Intel EPT 対応の場合、VMware が問題なく Intel EPT を通過するかどうか、および Hyper-V が Intel EPT を見つけるかどうかを確認できるかどうかはわかりません。私の場合、最初に VMware Workstation を試したときに、それがすぐにうまくいったのでわかりました。この問題についてはいろいろ調べましたが、直感としては、Nehalem または Core i7 と Intel VT をサポートするマザーボードを見つけることだと思います。それが賢明でしょう。Intel VT –x2 が必要だとありますが、私は使用していないので(必要だとも思いません)、これは誤解を生みます。ただし、正確な情報を入手できたときには、この投稿を更新します。
- ハイパーバイザーのネスティングは、実行速度が非常に遅くなることを意味しますが、SSD ディスク上のデータストアにネストされたハイパーバイザーをインストールすると、大いに役立ちます。
- 上記の 2 件のブログは、バージョン 4/7 のハードウェアまたはバージョン 8 のハードウェアを使用して VM を作成するための 2 通りの方法について説明しています。私は最初にバージョン 8 のハードウェアを使用しましたが、まったく機能せず、画面はただ真っ黒なままでした。そこで、両方の方法を組み合わせて微調整してみると、無事に機能しました。
- ネストされた Hyper-V マシンが常駐するポート グループは、無作為モードを「同意」に設定する必要があります。
- 一方のブログには、GUI を使用しないで、config ファイルに手動で入力する方が安定性が高いという注意事項が記されています。私もそう思いました。私が、Putty を使用してシェル セッションで config ファイルを変更したのは、そのためです。
- ESXi 5 または VMware Workstation 8 に Hyper-V 仮想マシンをインストールするためのヒントをお持ちではありませんか。ぜひ下記にコメントをお寄せください。